
让建站和SEO变得简单
让不懂建站的用户快速建站,让会建站的提高建站效率!

打败GPT-4o、仅次于o1!英伟达重磅开源超宽广模子--Nemotron
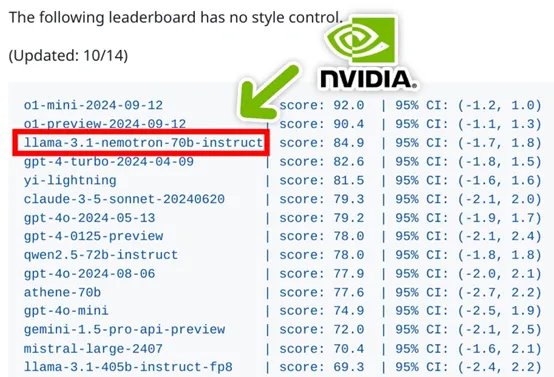
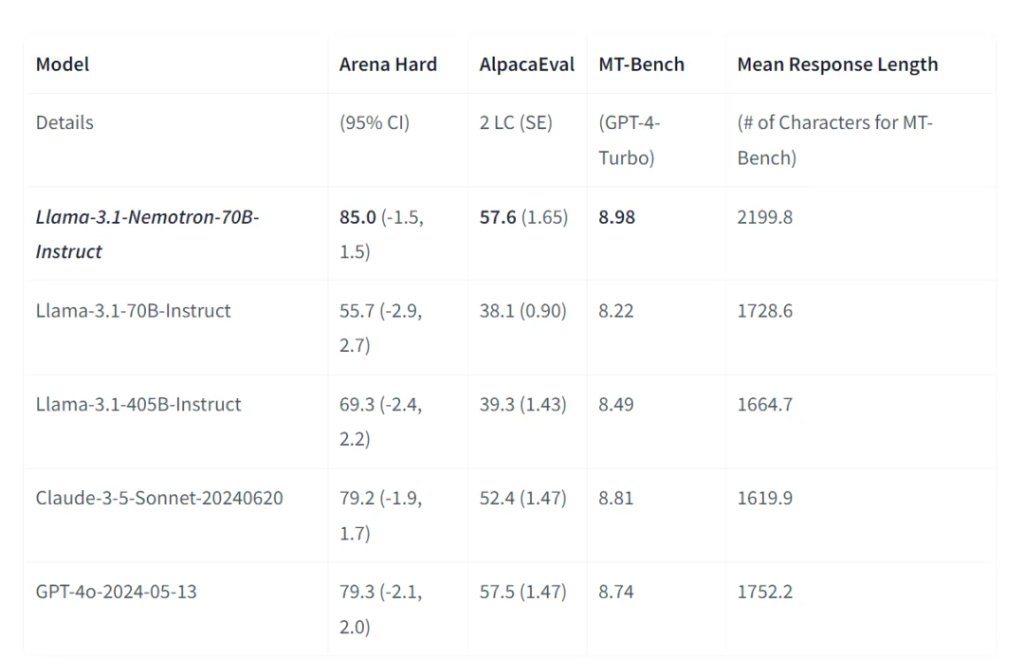
Nemotron打败了GPT-4o等140多个开闭源模子,仅次于OpenAI的最新模子o1。英伟达吸收夹杂磨砺口头,把Nemotron的磨砺数据集也开源了,还在RewardBench评测中达94.1分,朝上了同期险些统统其他模子的推崇。 环球AI辅导者英伟达(Nvidia)开源了超宽广模子——Llama-3.1-Nemotron-70B-Instruct。 笔据测试数据显露,这个模子还是打败GPT-4o、GPT-4turbo、Gemma-2、Gemini-1.5、Claude-3.5 sonn
-
Nemotron打败了GPT-4o等140多个开闭源模子,仅次于OpenAI的最新模子o1。英伟达吸收夹杂磨砺口头,把Nemotron的磨砺数据集也开源了,还在RewardBench评测中达94.1分,朝上了同期险些统统其他模子的推崇。
环球AI辅导者英伟达(Nvidia)开源了超宽广模子——Llama-3.1-Nemotron-70B-Instruct。
笔据测试数据显露,这个模子还是打败GPT-4o、GPT-4turbo、Gemma-2、Gemini-1.5、Claude-3.5 sonnet等140多个开闭源模子,仅次于OpenAI发布的最新模子o1。
Nemotron的基础模子是基于Llama-3.1-70B建立而成,这个没什么新奇。但在磨砺的经过使用了一种新的夹杂磨砺口头,将Bradley-Terry和Regression整个用于磨砺奖励模子。
值得一提的是,英伟达把Nemotron的磨砺数据集也开源了,这关于建立同类型或朝上Nemotron的模子颠倒攻击,因为这个是使用夹杂磨砺口头的要害所在。
有网友暗示,英伟达热衷于不断开源超强模子,一方面有大量资金资助他们的科研东谈主员研发,另外主要方针如故为了卖GPU以及培养建立生态。而Meta依托他的应酬帝国,在生意化和资金方面齐不愁。
最愁的即是那些大模子初创企业了,钱拼不外这些巨头,生意落地和名气更无须提。是以,好多小企业可能会因为巨头的碾压,很快会出现资金断裂等各式问题。
很兴隆看到AI规模的竞争,正在以惊东谈主的速率鼓动行业上前发展。
这然而重磅开源。

为了新模子,买两个4090爽一下吧。

模子是免费的,但入手的硬件可难免费啊。

我正在测试这个模子,我是一个高档AI用户说说使全心得:在生意写稿方面,似乎比Claude3和ChatGPT颖异一些。但它依然会犯一些无理,比拟于平时的3.1 70b Instruct,确乎更颖异。
Nvidia不错以1000倍更低的本钱完了这极少。要是Nvidia的确容许这样作念,那么将无东谈主能与之竞争。
翻新夹杂磨砺口头
在磨砺大模子的经过中,为了确保模子在内容使用中大约准确地通晓并罢职用户的指示指示,准确进行翻译、文本生成、问答等任务,奖励模子阐发了很攻击的作用,主要通过为模子的输出打分,率领模子生成更高质地的回答来完了。
当今,主流的奖励模子口头主要有Bradley-Terry和Regression两种:Bradley-Terry格调的奖励模子发源于统计学中的名次表面,通过最大化被采取反应和被隔断反应之间的奖励差距。这种口头强调在给定的指示下,用户会采取哪个反应,从而为模子提供了一种平直的、基于偏好的反馈。
Regression则模仿了热诚学中的评重量表,通过展望特定指示下反应的分数来磨砺模子。这种口头允许模子对反应的质地进行更良好的评估,但可能不如基于偏好的口头直不雅。
但这两种口头齐有显明的污点,Bradley-Terry需要用户在两个反应中采取一个;而转头格调的模子需要评分数据,用户需要为每个反应打分才能匡助模子进步性能。是以,英伟达平直把两个模子的优点放在整个使用来措置这个穷苦。
最初是需要建立一个包含评分和偏好瞩方针数据集HELPSTEER2-PREFERENCE。盘算东谈主员是在HELPSTEER2基础上添加偏好瞩目。
这些偏好瞩目不仅包括用户在两个反应中采取一个的偏好场地,还包括用户对这种偏好的强度评分。为了确保数据的质地和可讲授性,还要求瞩目者为他们的偏好提供书面阐明。
在磨砺这种新式夹杂口头时,盘算东谈主员使用AdamW优化器来磨砺模子,通过引入权重衰减和梯度编著来提高磨砺的清楚性和成果。
为了进一步提高模子性能,使用了ExPO在磨砺经过中对模子的权重进行外推,不错进一步提高模子的性能。不错使模子在磨砺时愈加热心那些相反较大的反应付,从而提高模子的分袂才调。
此外,盘算东谈主员还进行了粗拙的超参数搜索,以找到最好的学习率和KL刑事株连项。这些超参数关于模子的磨砺至关攻击,因为它们平直影响到模子的拘谨速率和最终性能。
HELPSTEER2-PREFERENCE数据集
为了建立这个多元化恬逸新的夹杂磨砺口头数据集,在数据瞩方针经过中,每一双回复齐经过3—5名标注者的评价。这些标注者需要从多个维度对每个回复进行评分,包括有用性、准确性、连贯性、复杂性和冗出息度等。
为了更好地通晓背后的原因,标注者还需要提供随意的翰墨阐明,讲授为何采取了某个回复行为更好的谜底。这种口头不仅增强了数据的透明度,也为后续分析提供了丰富的高下文信息。
盘算东谈主员还使用了严格的数据预处理门径来保证数据质地。举例,他们会识别出每个任务中雷同度最高的三个偏好瞩目,然后取这三个瞩方针平均值并四舍五入到最接近的整数,以此行为该任务的全体偏好得分。
同期,为了排斥那些标注者观点不合较大的样本,盘算东谈主员们会过滤掉那些瞩目之间相反朝上一定规模的任务。这些步伐共同作用,灵验进步了数据的可靠性和一致性。
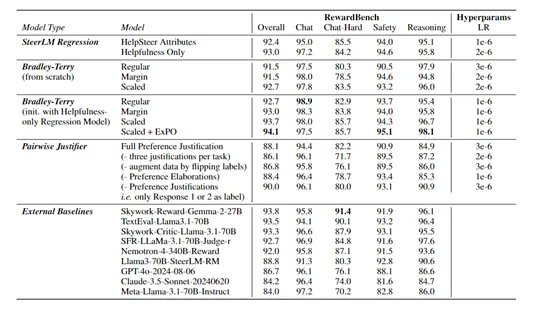
笔据测试数据显露,使用HELPSTEER2-PREFERENCE数据集磨砺的模子性能颠倒强,在RewardBench评测中达到了94.1的高分,朝上了同期险些统统其他模子的推崇。
本文起头:AIGC通达社区,原文标题:《打败GPT-4o、仅次于o1!英伟达重磅开源超宽广模子--Nemotron》
风险指示及免责条目
市集有风险,投资需严慎。本文不组成个东谈主投资漠视,也未探求到个别用户罕见的投资方针、财务情景或需要。用户应试虑本文中的任何观点、不雅点或论断是否适当其特定情景。据此投资,株连自夸。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
株连编著:王长生